MeloDraw is an online application that automatically searches melody contours similar to user’s line drawing input. The input drawing is converted into a melodic contour based on predefined rules and the melodic contour is then passed to the melody proposal model as a query to find similar melodies. The model has a bi-directional RNN autoencoder architecture trained with about 4000 contours of jazz solo melodies to learn the melody embedding space. Most similar melodies given the query are searched on the embedding space. We implemented the system as a web-based application so that anyone can easily access to it.
Creating an artwork is a process of configuring intangible images that creators have in their mind. For songwriters, it is thus natural that they often struggle to come up with appropriate melody which matches well what they are trying to express.
Our model enables creators to explore wide scope of new melodies by using another modality of expression, line drawing. It first converts the drawing pattern into a melodic contour vector and inspects the corresponding latent space to find out similar melodic contours from the existing dataset. It can be regarded as a form of assisted creativity since it expands the possibility of musical expressions to an unexperienced process.
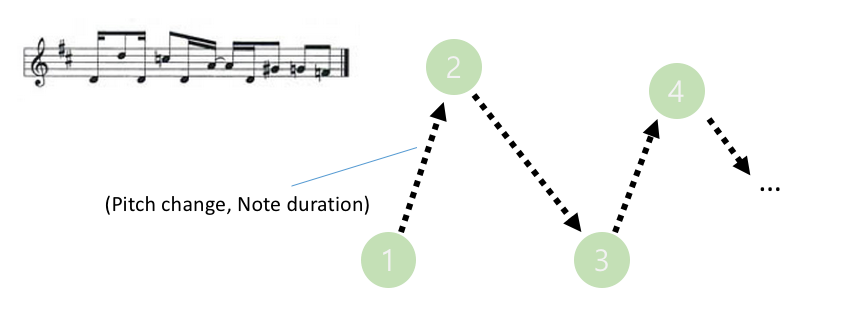
We converted the melody data into our data representation scheme, the melody contour vector. We excluded melodies with triplet beats and set 2-bar melody as a base unit of the data. After segmenting the tunes into 2-bar melodic sequence, we extracted a 2-dimensional vector (note duration, pitch interval) each.
For example, if 8th note of C is followed by 4th note of G, the input vector becomes (0.5, 7). This way, we obtained 4313 melodic sequences. The length of a vector varies depending on the number of notes the 2-bar sequence contains. Thus, in order to make sure all sequences have the same length, we set the length as 32 encodings of (note duration, pitch interval) and applied zero-padding for short sequences. The final input is of size 2-by-32.
contour form>
In the hope of capturing the inherent characteristics of melodic sequence, we tested various autoencoder architectures. Compared to Variational Auto-Encoder (VAE) which parameterizes the latent space into Gaussian distribution, the original autoencoder architecture gave more reasonable results in our experiment. We speculate that it attributes the small volume of the training data.
We also conducted further experiments by applying recurrent autoencoder in order to better reflect the sequential characteristics of the melody. Thus, we set our final model to the RNN bi-directional autoencoder.
Figure below shows that it successfully finds reasonably similar melodies from a given query. The model encodes the query melody into a latent vector and finds the closest ones by Euclidean distance in the embedded space. The original melody vectors corresponding to the closest embedded vectors are demonstrated.

latent space of recurrent autoencoder>
Here’s our demo video.
